from tensorflow import keras
keras.__version__
'2.4.0'
이 노트북은 케라스 창시자에게 배우는 딥러닝 책의 6장 1절의 코드 예제입니다. 책에는 더 많은 내용과 그림이 있습니다. 이 노트북에는 소스 코드에 관련된 설명만 포함합니다. 이 노트북의 설명은 케라스 버전 2.2.2에 맞추어져 있습니다. 케라스 최신 버전이 릴리스되면 노트북을 다시 테스트하기 때문에 설명과 코드의 결과가 조금 다를 수 있습니다.
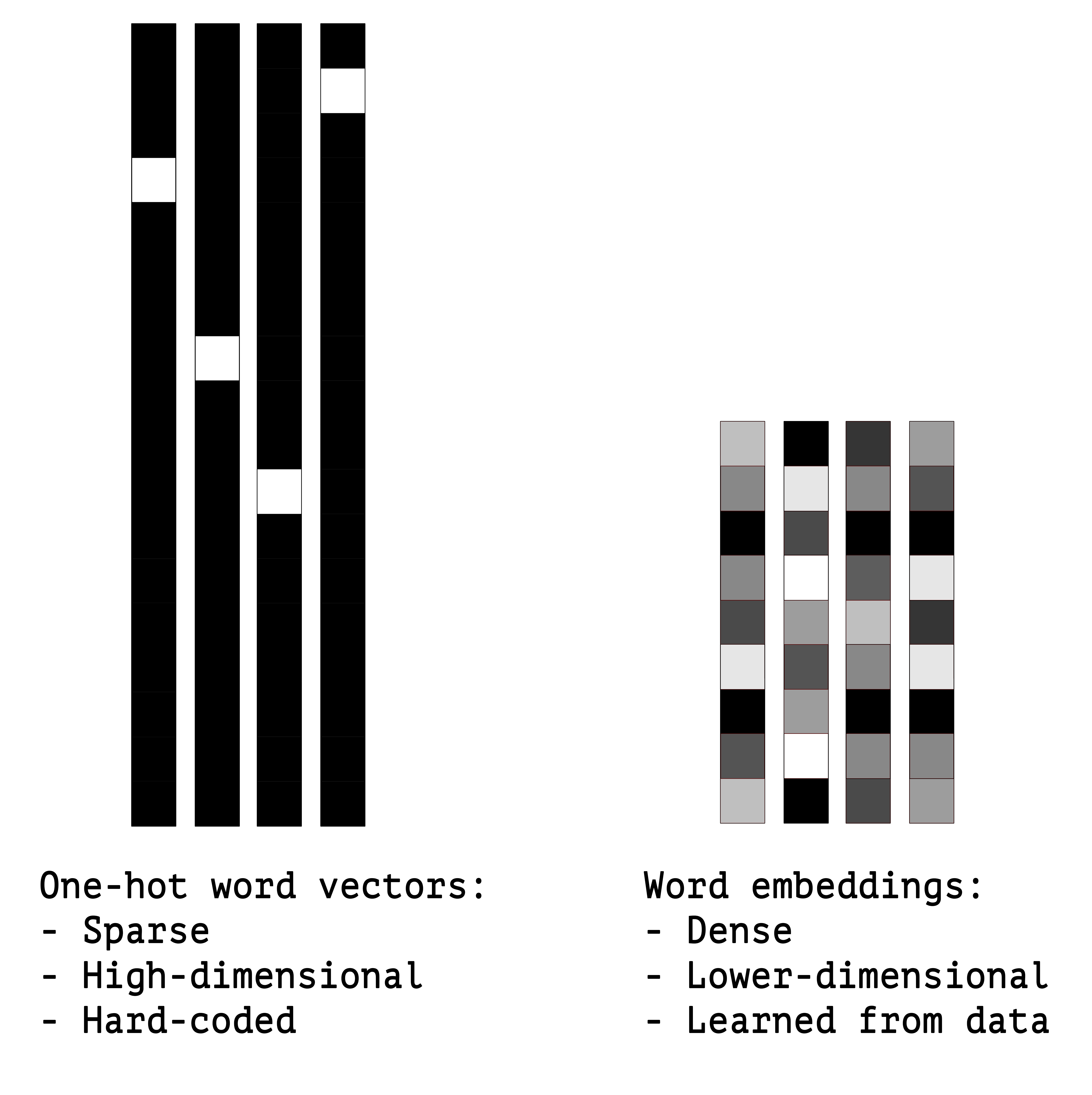
단어와 벡터를 연관짓는 강력하고 인기 있는 또 다른 방법은 단어 임베딩이라는 밀집 단어 벡터를 사용하는 것입니다. 원-핫 인코딩으로 만든 벡터는 희소하고(대부분 0으로 채워집니다) 고차원입니다(어휘 사전에 있는 단어의 수와 차원이 같습니다). 반면 단어 임베딩은 저차원의 실수형 벡터입니다(희소 벡터의 반대인 밀집 벡터입니다). 그림 6-2를 참고하세요. 원-핫 인코딩으로 얻은 단어 벡터와 달리 단어 임베딩은 데이터로부터 학습됩니다. 보통 256차원, 512차원 또는 큰 어휘 사전을 다룰 때는 1,024차원의 단어 임베딩을 사용합니다. 반면 원-핫 인코딩은 (20,000개의 토큰으로 이루어진 어휘 사전을 만들려면) 20,000차원 또는 그 이상의 벡터일 경우가 많습니다. 따라서 단어 임베딩이 더 많은 정보를 적은 차원에 저장합니다.
단어 임베딩을 만드는 방법은 두 가지입니다.
두 가지 모두 살펴보겠습니다.
Embedding 층을 사용해 단어 임베딩 학습하기¶단어와 밀집 벡터를 연관짓는 가장 간단한 방법은 랜덤하게 벡터를 선택하는 것입니다. 이 방식의 문제점은 임베딩 공간이 구조적이지 않다는 것입니다. 예를 들어 accurate와 exact 단어가 대부분 문장에서 비슷한 의미로 사용되지만 완전히 다른 임베딩을 가지게 됩니다. 심층 신경망이 이런 임의의 구조적이지 않은 임베딩 공간을 이해하기는 어렵습니다.
단어 벡터 사이에 조금 더 추상적이고 기하학적인 관계를 얻으려면 단어 사이에 있는 의미 관계를 반영해야 합니다. 단어 임베딩은 언어를 기하학적 공간에 매핑하는 것입니다. 예를 들어 잘 구축된 임베딩 공간에서는 동의어가 비슷한 단어 벡터로 임베딩될 것입니다. 일반적으로 두 단어 벡터 사이의 거리(L2 거리)는 이 단어 사이의 의미 거리와 관계되어 있습니다(멀리 떨어진 위치에 임베딩된 단어의 의미는 서로 다르고 반면 비슷한 단어들은 가까이 임베딩됩니다). 거리외에 임베딩 공간의 특정 방향도 의미를 가질 수 있습니다.
[...]
실제 단어 임베딩 공간에서 의미 있는 기하학적 변환의 일반적인 예는 '성별' 벡터와 '복수(plural)' 벡터입니다. 예를 들어 'king' 벡터에 'female' 벡터를 더하면 'queen' 벡터가 됩니다. 'plural' 벡터를 더하면 'kings'가 됩니다. 단어 임베딩 공간은 전형적으로 이런 해석 가능하고 잠재적으로 유용한 수천 개의 벡터를 특성으로 가집니다.
사람의 언어를 완벽하게 매핑해서 어떤 자연어 처리 작업에도 사용할 수 있는 이상적인 단어 임베딩 공간이 있을까요? 아마도 가능하겠지만 아직까지 이런 종류의 공간은 만들지 못했습니다. 사람의 언어에도 그런 것은 없습니다. 세상에는 많은 다른 언어가 있고 언어는 특정 문화와 환경을 반영하기 때문에 서로 동일하지 않습니다. 실제로 좋은 단어 임베딩 공간을 만드는 것은 문제에 따라 크게 달라집니다. 영어로 된 영화 리뷰 감성 분석 모델을 위한 완벽한 단어 임베딩 공간은 영어로 된 법률 문서 분류 모델을 위한 완벽한 임베딩 공간과 다를 것 같습니다. 특정 의미 관계의 중요성이 작업에 따라 다르기 때문입니다.
따라서 새로운 작업에는 새로운 임베딩을 학습하는 것이 타당합니다. 다행히 역전파를 사용해 쉽게 만들 수 있고 케라스를 사용하면 더 쉽습니다. Embedding 층의 가중치를 학습하면 됩니다.
from tensorflow.keras.layers import Embedding
# Embedding 층은 적어도 두 개의 매개변수를 받습니다.
# 가능한 토큰의 개수(여기서는 1,000으로 단어 인덱스 최댓값 + 1입니다)와 임베딩 차원(여기서는 64)입니다
embedding_layer = Embedding(1000, 64)
Embedding 층을 (특정 단어를 나타내는) 정수 인덱스를 밀집 벡터로 매핑하는 딕셔너리로 이해하는 것이 가장 좋습니다. 정수를 입력으로 받아 내부 딕셔너리에서 이 정수에 연관된 벡터를 찾아 반환합니다. 딕셔너리 탐색은 효율적으로 수행됩니다.
Embedding 층은 크기가 (samples, sequence_length)인 2D 정수 텐서를 입력으로 받습니다. 각 샘플은 정수의 시퀀스입니다. 가변 길이의 시퀀스를 임베딩할 수 있습니다. 예를 들어 위 예제의 Embedding 층에 (32, 10) 크기의 배치(길이가 10인 시퀀스 32개로 이루어진 배치)나 (64, 15) 크기의 배치(길이가 15인 시퀀스 64개로 이루어진 배치)를 주입할 수 있습니다. 배치에 있는 모든 시퀀스는 길이가 같아야 하므로(하나의 텐서에 담아야 하기 때문에) 작은 길이의 시퀀스는 0으로 패딩되고 길이가 더 긴 시퀀스는 잘립니다.
Embedding 층은 크기가 (samples, sequence_length, embedding_dimensionality)인 3D 실수형 텐서를 반환합니다. 이런 3D 텐서는 RNN 층이나 1D 합성곱 층에서 처리됩니다(둘 다 이어지는 절에서 소개하겠습니다).
Embedding 층의 객체를 생성할 때 가중치(토큰 벡터를 위한 내부 딕셔너리)는 다른 층과 마찬가지로 랜덤하게 초기화됩니다. 훈련하면서 이 단어 벡터는 역전파를 통해 점차 조정되어 이어지는 모델이 사용할 수 있도록 임베팅 공간을 구성합니다. 훈련이 끝나면 임베딩 공간은 특정 문제에 특화된 구조를 많이 가지게 됩니다.
이를 익숙한 IMDB 영화 리뷰 감성 예측 문제에 적용해 보죠. 먼저 데이터를 준비합니다. 영화 리뷰에서 가장 빈도가 높은 10,000개의 단어를 추출하고(처음 이 데이터셋으로 작업했던 것과 동일합니다) 리뷰에서 20개 단어 이후는 버립니다. 이 네트워크는 10,000개의 단어에 대해 8 차원의 임베딩을 학습하여 정수 시퀀스 입력(2D 정수 텐서)를 임베딩 시퀀스(3D 실수형 텐서)로 바꿀 것입니다. 그 다음 이 텐서를 2D로 펼쳐서 분류를 위한 Dense 층을 훈련하겠습니다.
from tensorflow.keras.datasets import imdb
from tensorflow.keras import preprocessing
# 특성으로 사용할 단어의 수
max_features = 10000
# 사용할 텍스트의 길이(가장 빈번한 max_features 개의 단어만 사용합니다)
maxlen = 20
# 정수 리스트로 데이터를 로드합니다.
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
# 리스트를 (samples, maxlen) 크기의 2D 정수 텐서로 변환합니다.
x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 2s 0us/step
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Embedding
model = Sequential()
# 나중에 임베딩된 입력을 Flatten 층에서 펼치기 위해 Embedding 층에 input_length를 지정합니다.
model.add(Embedding(10000, 8, input_length=maxlen))
# Embedding 층의 출력 크기는 (samples, maxlen, 8)가 됩니다.
# 3D 임베딩 텐서를 (samples, maxlen * 8) 크기의 2D 텐서로 펼칩니다.
model.add(Flatten())
# 분류기를 추가합니다.
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_split=0.2)
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, 20, 8) 80000 _________________________________________________________________ flatten (Flatten) (None, 160) 0 _________________________________________________________________ dense (Dense) (None, 1) 161 ================================================================= Total params: 80,161 Trainable params: 80,161 Non-trainable params: 0 _________________________________________________________________ Epoch 1/10 625/625 [==============================] - 3s 4ms/step - loss: 0.6669 - accuracy: 0.6367 - val_loss: 0.6125 - val_accuracy: 0.7026 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5372 - accuracy: 0.7543 - val_loss: 0.5207 - val_accuracy: 0.7384 Epoch 3/10 625/625 [==============================] - 2s 4ms/step - loss: 0.4587 - accuracy: 0.7897 - val_loss: 0.4969 - val_accuracy: 0.7514 Epoch 4/10 625/625 [==============================] - 2s 4ms/step - loss: 0.4208 - accuracy: 0.8098 - val_loss: 0.4921 - val_accuracy: 0.7606 Epoch 5/10 625/625 [==============================] - 2s 4ms/step - loss: 0.3945 - accuracy: 0.8241 - val_loss: 0.4905 - val_accuracy: 0.7564 Epoch 6/10 625/625 [==============================] - 2s 4ms/step - loss: 0.3731 - accuracy: 0.8351 - val_loss: 0.4941 - val_accuracy: 0.7574 Epoch 7/10 625/625 [==============================] - 2s 4ms/step - loss: 0.3541 - accuracy: 0.8443 - val_loss: 0.4998 - val_accuracy: 0.7610 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.3362 - accuracy: 0.8547 - val_loss: 0.5049 - val_accuracy: 0.7592 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.3190 - accuracy: 0.8643 - val_loss: 0.5118 - val_accuracy: 0.7570 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.3030 - accuracy: 0.8716 - val_loss: 0.5199 - val_accuracy: 0.7566
약 75% 정도의 검증 정확도가 나옵니다. 리뷰에서 20개의 단어만 사용한 것치고 꽤 좋은 결과입니다. 하지만 임베딩 시퀀스를 펼치고 하나의 Dense 층을 훈련했으므로 입력 시퀀스에 있는 각 단어를 독립적으로 다루었습니다. 단어 사이의 관계나 문장의 구조를 고려하지 않았습니다(예를 들어 이 모델은 “this movie is a bomb”와 “this movie is the bomb”를 부정적인 리뷰로 동일하게 다룰 것입니다). 각 시퀀스 전체를 고려한 특성을 학습하도록 임베딩 층 위에 순환 층이나 1D 합성곱 층을 추가하는 것이 좋습니다. 다음 절에서 이에 관해 집중적으로 다루겠습니다.
이따금 훈련 데이터가 부족하면 작업에 맞는 단어 임베딩을 학습할 수 없습니다. 이럴 땐 어떻게 해야 할까요?
풀려는 문제와 함께 단어 임베딩을 학습하는 대신에 미리 계산된 임베딩 공간에서 임베딩 벡터를 로드할 수 있습니다. 이런 임베딩 공간은 뛰어난 구조와 유용한 성질을 가지고 있어서 언어 구조의 일반적인 측면을 잡아낼 수 있습니다. 자연어 처리에서 사전 훈련된 단어 임베딩을 사용하는 이유는 이미지 분류 문제에서 사전 훈련된 컨브넷을 사용하는 이유와 거의 동일합니다. 충분한 데이터가 없어서 자신만의 좋은 특성을 학습하지 못하지만 꽤 일반적인 특성이 필요할 때입니다. 이런 경우에는 다른 문제에서 학습한 특성을 재사용하는 것이 합리적입니다.
단어 임베딩은 일반적으로 (문장이나 문서에 같이 등장하는 단어를 관찰하는) 단어 출현 통계를 사용하여 계산됩니다. 여기에는 여러 가지 기법이 사용되는데 신경망을 사용하는 것도 있고 그렇지 않은 방법도 있습니다. 단어를 위해 밀집된 저차원 임베딩 공간을 비지도 학습 방법으로 계산하는 아이디어는 요슈아 벤지오 등이 2000년대 초에 조사했습니다. 연구나 산업 애플리케이션에 적용되기 시작된 것은 Word2vec 알고리즘이 등장한 이후입니다. 이 알고리즘은 2013년 구글의 토마스 미코로프가 개발하였으며 가장 유명하고 성공적인 단어 임베딩 방법입니다. Word2vec의 차원은 성별 같은 구체적인 의미가 있는 속성을 잡아냅니다.
케라스의 Embedding 층을 위해 내려받을 수 있는 미리 계산된 단어 임베딩 데이터베이스가 여럿 있습니다. Word2vec은 그 중 하나입니다. 인기 있는 또 다른 하나는 2014년 스탠포드 대학의 연구자들이 개발한 GloVe(Global Vectors for Word Representation)입니다. 이 임베딩 기법은 단어의 동시 출현 통계를 기록한 행렬을 분해하는 기법을 사용합니다. 이 개발자들은 위키피디아 데이터와 커먼 크롤 데이터에서 가져온 수백만 개의 영어 토큰에 대해서 임베딩을 미리 계산해 놓았습니다.
GloVe 임베딩을 케라스 모델에 어떻게 사용하는지 알아보죠. Word2vec 임베딩이나 다른 단어 임베딩 데이터베이스도 방법은 같습니다. 앞서 보았던 텍스트 토큰화 기법도 다시 살펴보겠습니다. 원본 텍스트에서 시작해서 완전한 모델을 구성해 보겠습니다.
앞서 만들었던 것과 비슷한 모델을 사용하겠습니다. 문장들을 벡터의 시퀀스로 임베딩하고 펼친 다음 그 위에 Dense 층을 훈련합니다. 여기서는 사전 훈련된 단어 임베딩을 사용하겠습니다. 케라스에 포함된 IMDB 데이터는 미리 토큰화가 되어 있습니다. 이를 사용하는 대신 원본 텍스트 데이터를 다운로딩해서 처음부터 시작하겠습니다.
먼저 http://mng.bz/0tIo 에서 IMDB 원본 데이터셋을 다운로드하고 압축을 해제합니다.
훈련용 리뷰 하나를 문자열 하나로 만들어 훈련 데이터를 문자열의 리스트로 구성해 보죠. 리뷰 레이블(긍정/부정)도 labels 리스트로 만들겠습니다:
import os
imdb_dir = './datasets/aclImdb'
train_dir = os.path.join(imdb_dir, 'train')
labels = []
texts = []
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type)
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname), encoding='utf8')
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
이전 절에서 소개한 개념을 사용해 텍스트를 벡터로 만들고 훈련 세트와 검증 세트로 나누겠습니다. 사전 훈련된 단어 임베딩은 훈련 데이터가 부족한 문제에 특히 유용합니다(그렇지 않으면 문제에 특화된 임베딩이 훨씬 성능이 좋습니다). 그래서 다음과 같이 훈련 데이터를 처음 200개의 샘플로 제한합니다. 이 모델은 200개의 샘플을 학습한 후에 영화 리뷰를 분류할 것입니다.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
maxlen = 100 # 100개 단어 이후는 버립니다
training_samples = 200 # 훈련 샘플은 200개입니다
validation_samples = 10000 # 검증 샘플은 10,000개입니다
max_words = 10000 # 데이터셋에서 가장 빈도 높은 10,000개의 단어만 사용합니다
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print('%s개의 고유한 토큰을 찾았습니다.' % len(word_index))
data = pad_sequences(sequences, maxlen=maxlen)
labels = np.asarray(labels)
print('데이터 텐서의 크기:', data.shape)
print('레이블 텐서의 크기:', labels.shape)
# 데이터를 훈련 세트와 검증 세트로 분할합니다.
# 샘플이 순서대로 있기 때문에 (부정 샘플이 모두 나온 후에 긍정 샘플이 옵니다)
# 먼저 데이터를 섞습니다.
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
x_train = data[:training_samples]
y_train = labels[:training_samples]
x_val = data[training_samples: training_samples + validation_samples]
y_val = labels[training_samples: training_samples + validation_samples]
88582개의 고유한 토큰을 찾았습니다. 데이터 텐서의 크기: (25000, 100) 레이블 텐서의 크기: (25000,)
https://nlp.stanford.edu/projects/glove 에서 2014년 영문 위키피디아를 사용해 사전에 계산된 임베딩을 내려받습니다. 이 파일의 이름은 glove.6B.zip이고 압축 파일 크기는 823MB입니다. 400,000만개의 단어(또는 단어가 아닌 토큰)에 대한 100차원의 임베딩 벡터를 포함하고 있습니다. datasets 폴더 아래에 파일 압축을 해제합니다.
압축 해제한 파일(.txt 파일)을 파싱하여 단어(즉 문자열)와 이에 상응하는 벡터 표현(즉 숫자 벡터)를 매핑하는 인덱스를 만듭니다.
glove_dir = './datasets/'
embeddings_index = {}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'), encoding="utf8")
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('%s개의 단어 벡터를 찾았습니다.' % len(embeddings_index))
400000개의 단어 벡터를 찾았습니다.
그다음 Embedding 층에 주입할 수 있도록 임베딩 행렬을 만듭니다. 이 행렬의 크기는 (max_words, embedding_dim)이어야 합니다. 이 행렬의 i번째 원소는 (토큰화로 만든) 단어 인덱스의 i번째 단어에 상응하는 embedding_dim 차원 벡터입니다. 인덱스 0은 어떤 단어나 토큰도 아닐 경우를 나타냅니다.
embedding_dim = 100
embedding_matrix = np.zeros((max_words, embedding_dim))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if i < max_words:
if embedding_vector is not None:
# 임베딩 인덱스에 없는 단어는 모두 0이 됩니다.
embedding_matrix[i] = embedding_vector
이전과 동일한 구조의 모델을 사용하겠습니다:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Flatten, Dense
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_2 (Embedding) (None, 100, 100) 1000000 _________________________________________________________________ flatten_1 (Flatten) (None, 10000) 0 _________________________________________________________________ dense_1 (Dense) (None, 32) 320032 _________________________________________________________________ dense_2 (Dense) (None, 1) 33 ================================================================= Total params: 1,320,065 Trainable params: 1,320,065 Non-trainable params: 0 _________________________________________________________________
Embedding 층은 하나의 가중치 행렬을 가집니다. 이 행렬은 2D 부동 소수 행렬이고 각 i번째 원소는 i번째 인덱스에 상응하는 단어 벡터입니다. 간단하네요. 모델의 첫 번째 층인 Embedding 층에 준비된 GloVe 행렬을 로드하세요:
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
추가적으로 Embedding 층을 동결합니다(trainable 속성을 False로 설정합니다). 사전 훈련된 컨브넷 특성을 사용할 때와 같은 이유입니다. 모델의 일부는 (Embedding 층처럼) 사전 훈련되고 다른 부분은 (최상단 분류기처럼) 랜덤하게 초기화되었다면 훈련하는 동안 사전 훈련된 부분이 업데이트되면 안됩니다. 이미 알고 있던 정보를 모두 잃게 됩니다. 랜덤하게 초기화된 층에서 대량의 그래디언트 업데이트가 발생하면 이미 학습된 특성을 오염시키기 때문입니다.
모델을 컴파일하고 훈련합니다:
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_data=(x_val, y_val))
model.save_weights('pre_trained_glove_model.h5')
Epoch 1/10 7/7 [==============================] - 1s 148ms/step - loss: 2.1136 - accuracy: 0.4950 - val_loss: 0.8917 - val_accuracy: 0.5003 Epoch 2/10 7/7 [==============================] - 1s 122ms/step - loss: 0.6376 - accuracy: 0.6450 - val_loss: 0.7839 - val_accuracy: 0.5090 Epoch 3/10 7/7 [==============================] - 1s 128ms/step - loss: 0.5523 - accuracy: 0.7000 - val_loss: 0.7312 - val_accuracy: 0.5215 Epoch 4/10 7/7 [==============================] - 1s 128ms/step - loss: 0.3093 - accuracy: 0.9100 - val_loss: 0.9494 - val_accuracy: 0.5021 Epoch 5/10 7/7 [==============================] - 1s 131ms/step - loss: 0.2186 - accuracy: 0.9500 - val_loss: 1.8341 - val_accuracy: 0.4999 Epoch 6/10 7/7 [==============================] - 1s 125ms/step - loss: 0.3560 - accuracy: 0.8550 - val_loss: 0.7369 - val_accuracy: 0.5548 Epoch 7/10 7/7 [==============================] - 1s 117ms/step - loss: 0.1208 - accuracy: 0.9800 - val_loss: 1.1336 - val_accuracy: 0.5090 Epoch 8/10 7/7 [==============================] - 1s 123ms/step - loss: 0.0783 - accuracy: 0.9950 - val_loss: 1.2085 - val_accuracy: 0.5054 Epoch 9/10 7/7 [==============================] - 1s 124ms/step - loss: 0.0727 - accuracy: 0.9900 - val_loss: 1.5593 - val_accuracy: 0.5009 Epoch 10/10 7/7 [==============================] - 1s 131ms/step - loss: 0.1183 - accuracy: 0.9350 - val_loss: 1.1931 - val_accuracy: 0.5236
이제 모델의 성능을 그래프로 그려 보겠습니다:
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()


이 모델은 과대적합이 빠르게 시작됩니다. 훈련 샘플 수가 작기 때문에 놀라운 일은 아닙니다. 같은 이유로 검증 정확도와 훈련 정확도 사이에 차이가 큽니다. 검증 정확도는 50% 후반을 달성한 것 같습니다.
훈련 샘플 수가 적기 때문에 어떤 샘플 200개를 선택했는지에 따라 성능이 크게 좌우됩니다. 여기서는 샘플들을 랜덤하게 선택했습니다. 만약 선택한 샘플에서 성능이 나쁘면 예제를 위해서 랜덤하게 200개의 샘플을 다시 추출하세요(실전에서는 훈련 데이터를 고르지 않습니다).
사전 훈련된 단어 임베딩을 사용하지 않거나 임베딩 층을 동결하지 않고 같은 모델을 훈련할 수 있습니다. 이런 경우 해당 작업에 특화된 입력 토큰의 임베딩을 학습할 것입니다. 데이터가 풍부하게 있다면 사전 훈련된 단어 임베딩보다 일반적으로 훨씬 성능이 높습니다. 여기서는 훈련 샘플이 200개뿐이지만 한 번 시도해 보죠:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Flatten, Dense
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_data=(x_val, y_val))
Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_3 (Embedding) (None, 100, 100) 1000000 _________________________________________________________________ flatten_2 (Flatten) (None, 10000) 0 _________________________________________________________________ dense_3 (Dense) (None, 32) 320032 _________________________________________________________________ dense_4 (Dense) (None, 1) 33 ================================================================= Total params: 1,320,065 Trainable params: 1,320,065 Non-trainable params: 0 _________________________________________________________________ Epoch 1/10 7/7 [==============================] - 1s 152ms/step - loss: 0.6972 - accuracy: 0.4550 - val_loss: 0.6931 - val_accuracy: 0.5106 Epoch 2/10 7/7 [==============================] - 1s 138ms/step - loss: 0.4689 - accuracy: 0.9800 - val_loss: 0.6973 - val_accuracy: 0.5123 Epoch 3/10 7/7 [==============================] - 1s 126ms/step - loss: 0.2338 - accuracy: 0.9900 - val_loss: 0.6991 - val_accuracy: 0.5185 Epoch 4/10 7/7 [==============================] - 1s 133ms/step - loss: 0.0984 - accuracy: 1.0000 - val_loss: 0.7184 - val_accuracy: 0.5203 Epoch 5/10 7/7 [==============================] - 1s 134ms/step - loss: 0.0473 - accuracy: 1.0000 - val_loss: 0.7096 - val_accuracy: 0.5224 Epoch 6/10 7/7 [==============================] - 1s 132ms/step - loss: 0.0226 - accuracy: 1.0000 - val_loss: 0.7270 - val_accuracy: 0.5249 Epoch 7/10 7/7 [==============================] - 1s 134ms/step - loss: 0.0133 - accuracy: 1.0000 - val_loss: 0.7217 - val_accuracy: 0.5225 Epoch 8/10 7/7 [==============================] - 1s 130ms/step - loss: 0.0076 - accuracy: 1.0000 - val_loss: 0.7263 - val_accuracy: 0.5246 Epoch 9/10 7/7 [==============================] - 1s 130ms/step - loss: 0.0047 - accuracy: 1.0000 - val_loss: 0.7399 - val_accuracy: 0.5291 Epoch 10/10 7/7 [==============================] - 1s 134ms/step - loss: 0.0029 - accuracy: 1.0000 - val_loss: 0.7371 - val_accuracy: 0.5265
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()


검증 정확도는 50% 초반에 멈추어 있습니다. 이 예제에서는 사전 훈련된 단어 임베딩을 사용하는 것이 임베딩을 함께 훈련하는 것보다 낫습니다. 훈련 샘플의 수를 늘리면 금새 상황이 바뀝니다. 연습삼아 한 번 확인해 보세요.
훈련 샘플의 수를 2000개로 늘려서 확인해 보겠습니다.
training_samples = 2000
x_train = data[:training_samples]
y_train = labels[:training_samples]
x_val = data[training_samples: training_samples + validation_samples]
y_val = labels[training_samples: training_samples + validation_samples]
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_data=(x_val, y_val))
Epoch 1/10 63/63 [==============================] - 2s 24ms/step - loss: 0.6457 - accuracy: 0.6070 - val_loss: 0.6918 - val_accuracy: 0.5947 Epoch 2/10 63/63 [==============================] - 1s 22ms/step - loss: 0.1605 - accuracy: 0.9855 - val_loss: 0.6257 - val_accuracy: 0.6669 Epoch 3/10 63/63 [==============================] - 1s 23ms/step - loss: 0.0190 - accuracy: 1.0000 - val_loss: 0.6417 - val_accuracy: 0.6889 Epoch 4/10 63/63 [==============================] - 1s 23ms/step - loss: 0.0015 - accuracy: 1.0000 - val_loss: 0.7208 - val_accuracy: 0.6963 Epoch 5/10 63/63 [==============================] - 1s 23ms/step - loss: 9.2584e-05 - accuracy: 1.0000 - val_loss: 0.7846 - val_accuracy: 0.7031 Epoch 6/10 63/63 [==============================] - 1s 21ms/step - loss: 5.6782e-06 - accuracy: 1.0000 - val_loss: 0.8604 - val_accuracy: 0.7064 Epoch 7/10 63/63 [==============================] - 1s 23ms/step - loss: 6.2126e-07 - accuracy: 1.0000 - val_loss: 0.9280 - val_accuracy: 0.7070 Epoch 8/10 63/63 [==============================] - 1s 23ms/step - loss: 1.3104e-07 - accuracy: 1.0000 - val_loss: 0.9929 - val_accuracy: 0.7072 Epoch 9/10 63/63 [==============================] - 1s 22ms/step - loss: 4.8818e-08 - accuracy: 1.0000 - val_loss: 1.0220 - val_accuracy: 0.7070 Epoch 10/10 63/63 [==============================] - 1s 23ms/step - loss: 2.6975e-08 - accuracy: 1.0000 - val_loss: 1.0451 - val_accuracy: 0.7074
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()


훈련 샘플의 수를 늘리니 단어 임베딩을 같이 훈련하는 모델의 검증 정확도가 70%를 넘었습니다.
마지막으로 테스트 데이터에서 모델을 평가해 보죠. 먼저 테스트 데이터를 토큰화해야 합니다:
test_dir = os.path.join(imdb_dir, 'test')
labels = []
texts = []
for label_type in ['neg', 'pos']:
dir_name = os.path.join(test_dir, label_type)
for fname in sorted(os.listdir(dir_name)):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname), encoding="utf8")
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
sequences = tokenizer.texts_to_sequences(texts)
x_test = pad_sequences(sequences, maxlen=maxlen)
y_test = np.asarray(labels)
그다음 이 절의 첫 번째 모델을 로드하고 평가합니다:
model.load_weights('pre_trained_glove_model.h5')
model.evaluate(x_test, y_test)
782/782 [==============================] - 2s 3ms/step - loss: 1.1996 - accuracy: 0.5226
[1.1996161937713623, 0.5226399898529053]
테스트 정확도는 겨우 50% 정도입니다. 적은 수의 훈련 샘플로 작업하는 것은 어려운 일이군요!